Spark - Pandas/PySpark - S3 integration
Main Content
If you want to skip the introduction section, you can jump to here
-
Why S3 ? (Brief Intro)
Amazon S3 (Simple Storage Service) is a secure, scalable, highly durable (This means that data survives even if two data centers go down at the same time 1) storage system that easily intergrates with the other AWS services. It is to be noted that S3 is not a file system.
-
Why Parquet?
Apache Parquet is a columnar storage format available to any project in the Hadoop ecosystem, regardless of the choice of data processing framework, data model or programming language2. Parquet file format integrates well with Apache Spark and languages like Scala. Here is a simple and short blog explaining why Parquet file format is preferred for Big Data Processing.
-
Why Spark? (Brief Intro)
Apache Spark is an open source, parallel processsing, unified analytics engine for big data processing. It provides high-level APIs with Python, Java, and R and built-in modules for streaming, SQL, machine learning, and graph processing 3. Spark is the most-widely used Big Data Processing framework.
Writing a Spark dataframe in parquet format to S3 is really dreadful. I could not think of another anology than Rachel’s dessert for thanksgiving in the sitcom Friends4. It had Custard which is good, it had Jam, again very good, and also meat - yet again very very good. But all three going together would make a dreadful combination.

-
Why PySpark + Parquet + S3 ? (Brief Intro)
But integrating Spark and Parquet with AWS S3 is vexing to an extent, especially when you have batch-jobs that run daily to take dump of huge amount of processed data in parquet format. The main issue would be the time taken to write or copy parquet files from a Spark Dataframe to S3. But changing few configrations in the Spark Config file could reduce the time taken.
But before delving into the Spark Config file let’s analyse what happens when Spark writes parquet in s3.
There are three filesystem clients that Hadoop used/uses to write to S3.
s3://,s3n://ands3a://.-
s3://filesystem is primal S3 store in Hadoop, but it is now deprecated. Hadoop insists on migrating the data ons3://to the newer filesystems. 5 -
s3n://is the primal ‘native’ filesystem. But it is known to have certain bugs and issues. It can upload objects upto size 5GB in S3. -
s3a://is the latest filesystem that Hadoop uses to interact with S3. It can read those objects that were written withs3n://and removes the constrainsts limitation ofs3n://and can support upto 5TB sized objects. Hadoop officially recommends the use ofs3a://6. Buts3a://is not supported by Amazon EMR service.
-
Major Challenge
-
The major challenge while dumping parquet to s3 is time taken. While working with PySpark and dumping processed Parquet files by an ETL batch job to S3, I have experienced considerable time lag in writing. The time taken to write to S3 increments when you have a large number of files with relatively low size (of <10 MBs). After researching through numerous articles and documentation, I have inferred that the below given Spark configuration changes would pace up the parquet file write process to S3.
-
How to improve the time taken to write a spark DF in parquet format to S3 ?
-
Configuration Changes.
The below given configuration changes can be applied to the Spark to reduce the time taken to write parquet files to S3.
-
The data written to an
s3a://OutputStreamfilesystem is not written incrementally, rather it is buffered to a disk untill the stream is complete or closed. This can make the output/write process incredibly slow. As per the official Hadoop documentation 7, the time taken for output stream to close is propotional to data streamed to the buffer and the inversely proportional to the network bandwidth available (from the host to S3). This is only intuitive. The larger the amount of data, it takes longer time to stream into the buffer. The higher bandwidth you have, the faster (less time) it would be to complete the buffering to the stream. Therefore the execution time forOutputStreamto close is of theO(data/bandwidth)7. This creates certain issues like the data is lost if the upload fails beforeOutputStream.close()is called. -
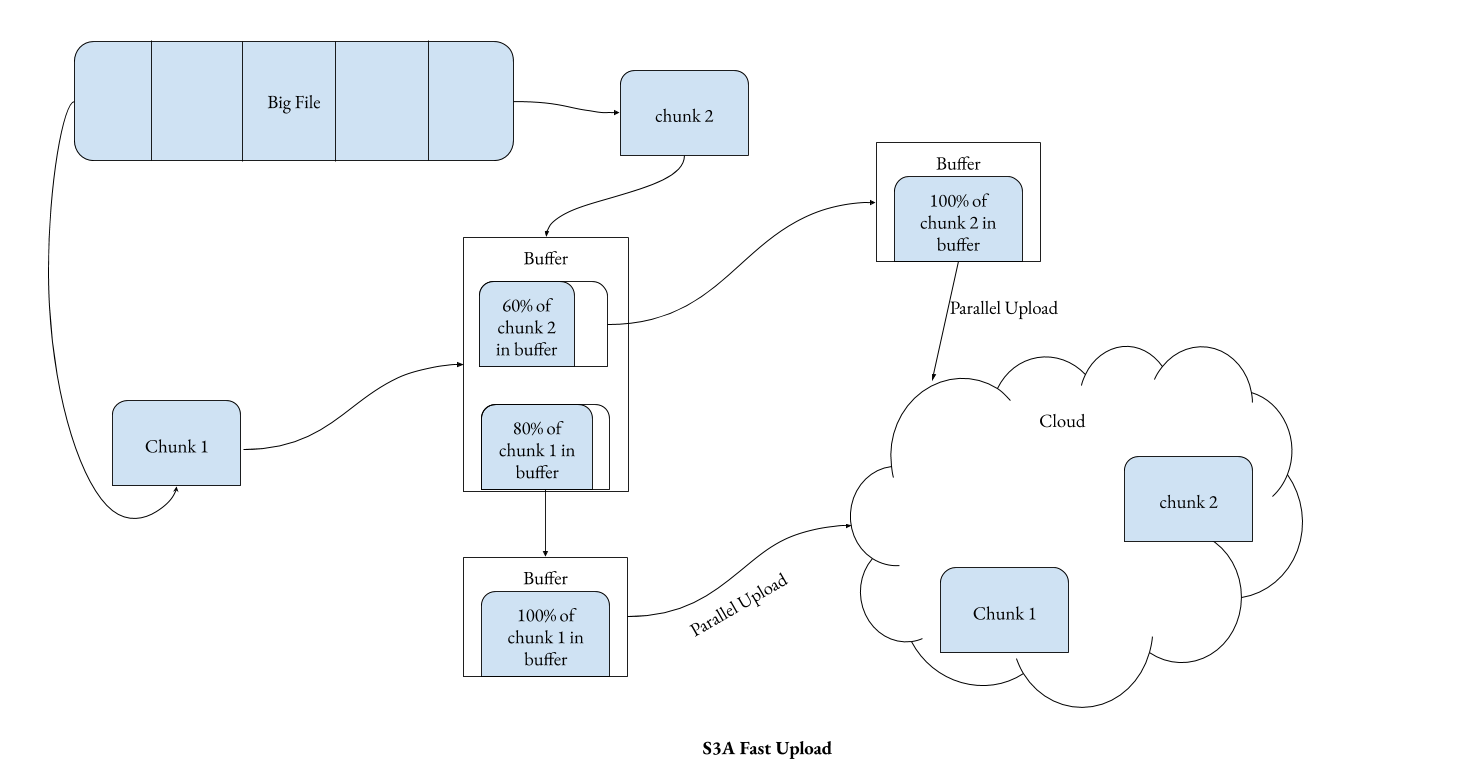
New method called S3a Fast Upload Stream was introduced in Hadoop 2.7.
- S3a Fast Upload Stream uploads large files as blocks of a particular size.
- The size of each block is configured by
fs.s3a.multipart.size. - The number of each active blocks that a single S3a Fast Upload Stream can use is determined by
fs.s3a.fast.upload.active.blocks = 8
This method breaks a large files into blocks/chunks, then it buffers each block into a buffer (disk, on-heap or JVM memory). When the size of the chunk reaches the size
fs.s3a.multipart.size, it starts uploading that block. Parallely, other blocks would also be uploaded to the cloud in the background, increasing the efficiency.Moreover, the buffer can be either Disk or heap of JVM, or JVM Memory. The disk is not recommended if the upload process that you are running is time critical. But certainly, the heap and JVM memory would come with a memory overhead.
When you choose disk as the buffer, you need to specify the directory in which the buffered chunks are stored. The directory/directories is configured by
fs.s3a.buffer.dir. This is ignored if you choose JVM heap or off-heap JVM memory. If you use JVM - heap or off-heap memory, then the stream would requirefs.s3a.multipart.size * fs.s3a.fast.upload.active.blockssize of memory.Below given configuration is the one advised for faster upload. You maychange
fs.s3a.multipart.sizeandfs.s3a.fast.upload.active.blocksas per your use case. -
fs.s3a.fast.upload = true fs.s3a.fast.upload.buffer = bytebuffer fs.s3a.multipart.size = 100M fs.s3a.fast.upload.active.blocks = 8Also
fs.s3a.impl- the s3a FileSystem implementation, must be keptorg.apache.hadoop.fs.s3a.S3AFileSystemandfs.s3a.multipart.purgemust befalselest all old uploads alive for more thanfs.s3a.multipart.purge.agewould be terminated by other applications and users.fs.s3a.fast.upload = true fs.s3a.fast.upload.buffer = bytebuffer fs.s3a.multipart.size = 100M fs.s3a.fast.upload.active.blocks = 8 fs.s3a.impl = org.apache.hadoop.fs.s3a.S3AFileSystem fs.s3a.multipart.purge = false
Other configuration changes are
spark.hadoop.mapreduce.fileoutputcommitter.algorithm.version = 2 spark.sql.parquet.mergeSchema = false spark.hadoop.parquet.enable.summary-metadata = false spark.sql.parquet.filterPushdown = true spark.sql.hive.metastorePartitionPruning = trueThe FileOutputCommitter algorithm version 1 uses a final rename operation as the mechanism for committing finished work at the end of a job. Because S3 renames are actually two operations (copy and delete), performance can be significantly impacted. FileOutputCommitter algorithm version 2 does less renaming at the end of a job than the “version 1” algorithm. As it still uses
rename()to commit files, it is unsafe to use when the object store does not have consistent metadata/listings.The Parquet data source merges schemas collected from all data files, else the schema is picked from the summary file or a random data file if no summary file is available. Since merging schema is a highly expensive operation,
spark.sql.parquet.mergeSchemashould be keptfalsefor faster processing.When summary-metadata is enabled spark tried to check the schema and read summary-metadata for all the files that is written. This takes time and would be consuming a major portion of your upload process if you have numerous files of small size (<10MB). Therefore
spark.hadoop.parquet.enable.summary-metadatamust be keptfalseto optimize your upload process.Another tweak which would help you optimize your process is Filter Pushdown algorithm. Filter Pushdown is an optimization algorithms that weeds the unwanted columns and to use index information to filter out extraneous metadata. This helps to reduce the data improving the upload process.
As per the official spark documentation
spark.sql.hive.metastorePartitionPruningmust be set true 8more about optimising spark for s3 can be found here and optimising spark for parquet and ORC files can be foune here.
-
-
Partitioning and No of Slaves/Worker in Standalone mode
-
-
Alternatives - PySpark to Pandas -
Another way to write spark dataframe to parquet is to convert the sparkDF to pandasDF.
Say an e-commerce company has a list of customers in Customer Table, and you want to keep all of their data separately catogarized according to their country. Then, you read the table as a sparkDF and then process it and then convert the sparkDF to pandasDF. Once you have the pandasDF - filter them according to thier country and write each country specific DF as parquet to S3. In this scenario, where the filtered DF is very small compared to the original DF, converting to pandasDF from sparkDF to write to S3 have been highly advantegeous.
There are multiple ways to write pandas to S3. All methods include uploading a bytestream object to S3.
- One way is to write the pandasDF to parquet using
df.to_parquet()method and then read the parquet file as bytestream and upload to S3. Thisto_parquet()method uses either PyArrow engine or fastparquet engine. - Another way is to use the
s3fslibrary which internally uses fasrparquet engine to write to S3. - A third way to write to S3 is to use
to_parquet()to write to aStringIO()buffer and then writing this buffered stream to S3. The example is shown here.
- One way is to write the pandasDF to parquet using
-
User should have an Cost Benefit Analysis of converting sparkDF to pandasDF and writing to S3. There is an added memory and time overhead of converting to the sparkDF to pandasDF. Thus an incisive analysis required before proceding to use this approach.
References
-
https://codeburst.io/amazon-s3-pros-cons-and-how-to-use-it-with-javascript-701fffc89154 ↩
-
https://hadoop.apache.org/docs/current/hadoop-aws/tools/hadoop-aws/index.html ↩
-
https://stackoverflow.com/questions/33356041/technically-what-is-the-difference-between-s3n-s3a-and-s3 ↩
-
https://hadoop.apache.org/docs/current/hadoop-aws/tools/hadoop-aws/index.html#Stabilizing:_S3A_Fast_Upload ↩ ↩2
-
https://spark.apache.org/docs/latest/sql-data-sources-parquet.html ↩