AWS Batch Jobs
This blog is about AWS Batch Jobs and various ways you can create workflows using them.
-
Why or When should we use AWS Batch Jobs?
When you need real-time analytics, real-time data you should use stream processing. In case of live telecast or analytics on a YouTube live or FaceBook live (like audio transcript, facial recognition etc.) or analytics on real time stock prices one should use stream processing.
But when you require updated data periodically - say over a day say the opening and closing prices of a set of stocks or monthly revenue of the company or quarterly performance of the company - one should use batch processing. If you opt for Batch processing, the next question is why use AWS Batch Jobs. Certainly there are many batch processing services, but this article would explain how to use AWS Batch Jobs rather than why use AWS Batch. AWS Batch is highly scalabe, secure and it easily integrates with other AWS services and it perfectly befits your batch processing if your infrastructure solely rests on AWS Cloud. This article does not explain the prons and cons of using AWS Batch Jobs.
-
How to setup a Batch Job?
-
IAM Roles and Permissions.
Identity and Access Management service of AWS allows you to securely access and control AWS resource that allows you to have granular access. AWS provides this service free of any cost. Obviously AWS do not want their cloud security to be compromised at any cost. As AWS Batch is one of the AWS Cloud services, it requires your IAM to be configured before using AWS Batch.
One should setup their IAM Roles and have permissions and policies to create a Compute Environment, to schedule and run the batch jobs. The official AWS Batch Jobs documentation explains how to setup the IAM Roles and Permissions.
-
Setup the Environment
Before delving to setting up the environment, let’s see few more definitions pertaining to the AWS Batch Jobs.
-
Jobs: The basic unit of work executed by AWS Batch. 1 It is executed as containerized applications in ECS. A job is abraction of a single container in ECS and its Job definition parameters. You can read about submitting the job over here.
-
Jobs Definition: It delineates how a job would be run. It specifies properties such as which docker image to use, what IAM Role should be assigned to the container etc. An example Job definition can be found here. You can read in detail about job definition over here.
-
Compute Environments: It is the environment in which the job would run. It allocates compute resources and scale them dynamically according to the resource requirements of the job. Once your IAM Roles, Permissions and Policies are setup. You have to create your Compute Environement. This is the environment where your batch jobs would run. You can create multiple Compute Environments.
-
Job Queue: Jobs submitted get executed in queues called Job Queues. Each job queue has one or more compute environments attached to it with each compute environment having its own priority. The jobs in the would also have priority.
- The jobs with the highest priority is executed first.
- The computer environment (if available) with the highest priority is choosen to execute the jobs.
Jobs and Jobs Definitions are like objects and class definitions. Objects are instances of a class. Similarly a job is a process that is defined by the template Job Definition. A single job definition can run multiple jobs, with each jobs having its own unique JobId.
For a given computer envirornment, the queues have priorities. A compute environment would. execute a job from the highest proirity queue. (That job would have the highest priority within the queue)
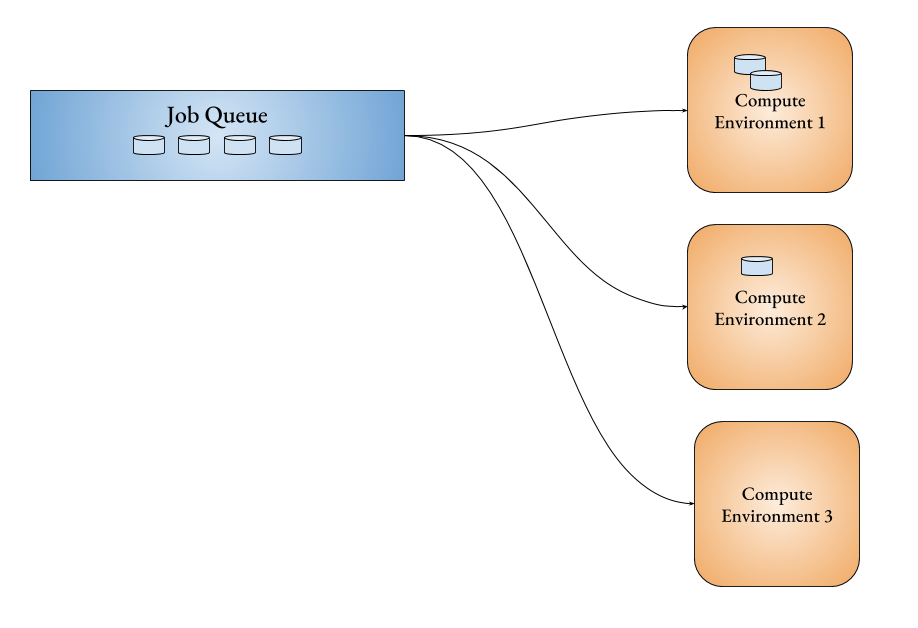
In the above diagram, the job 1 has higher priority in the job queue than job 2 which has higher priority than job 3 and so on. So does the compute environment. The compute environment 1 has higher priority than compute environment 2 than compute environment 3. So when job 1 and job 2 goes to a highest prior compute environment 1, the next jobs in queue would be executed in the next prior compute environment. So jobs 3 and 4 go to compute environment 2 and job 5 goes to computer environment 3. Now, if job 1 gets finished before job 6 is executed, the slot of compute environment 1 is free. Therefore, job 6 would get executed in compute environment 1 even though compute environment 3 has a slot free for a job.
The flow for creating a batch job in AWS Batch is given below
create a compute environment —> create job queue —> create a job definition —> submit a job
-
-
Docker Image
Each job runs as a container, hence each jobs requires a docker image that it would pull from the repository and build and deploy the container in an EC2 instance. The docker respository can be either the Docker Hub registry or the AWS EKR. If you choose an image from the AWS EKR, you should
aws_account_id.dkr.ecr.region.amazonaws.com/my-web-app:latest2. -
Resources
The resources that are allotted to the job includes vCPUs and Memory. vCPU (Virtual CPUs) must be atleast 1. Memory specified would the maximum memory that the job can have during its execution. If the container exceeds this memory limit, it is killed. The min. memory to be specified is 4MiB2.
Once the docker image and the resources are specified in the job definition after job queue and compute environment creation, you can submit a job.
-
-
How to setup a Batch Workflow?
Most often a batch process would be a part of the batch workflow. For instance, for the post-trade analytics, one has to filter the data, then process the data. After the data processing, one might need to do modeling (machine learning or statistical modeling) on it to derive insights. Each part of the post-trade analytics can be a batch process having depedency on the job preceding it. As each stage of the post-trade analytics had different computational requirements, it is optimal to run each stage as a different batch job in the pipeline.
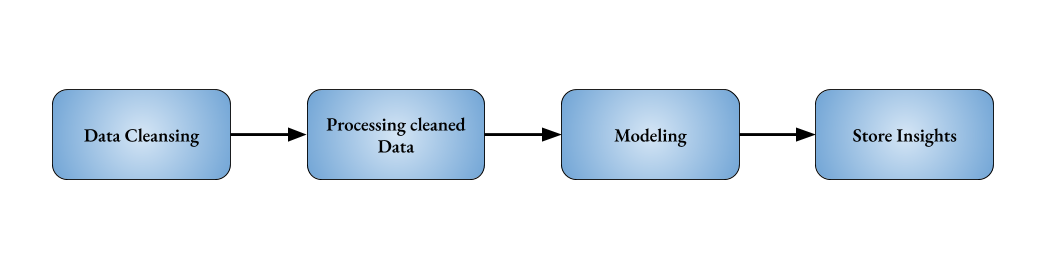
To implement this workflow. You have to give the jobId of the preceding job during the job submission. The jobId of Data Cleansing be specified at the submission of Processing Cleaned Data. The jobId of the Processing Cleaned Data must be specified at the submission of Modeling. And jobId of Modeling must be specified at the submission of Store Insights.
This sounds very simple to implement via AWS Console. But the issues is to automate this process. The jobId is unique for a job. Two jobs of the same job definition will have different but unique jobIds. This makes it different as everytime one needs to input the jobId of the preceding job to the present job if it has dependancy on the previous one.
I know it is bit hard to digest. Let me explain with an example.
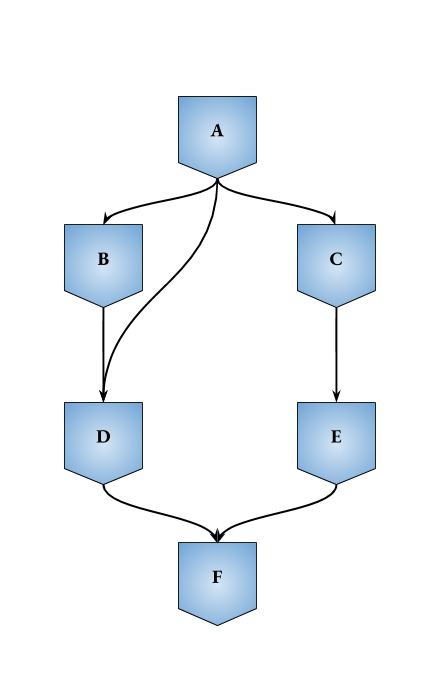
In the above given workflow:
- Jobs B, C, D depends on A
- Job D also depends on B
- Job E depends on C
- Job F depends on D and E.
Though jobs definitions might be permanent for each of the jobs. The jobIds would be changing after each run. That means you have to submit the new jobId at the time of the submission each time you iterate this workflow.
B depends on A(
jobId=e3421f) - 1st time run B depends on A(
jobId=h131jk) - 2nd time run.To automate this workflow, one has to create a master batch job - with minimal vCPU and minimal memory.
-
Master Job: How it works?
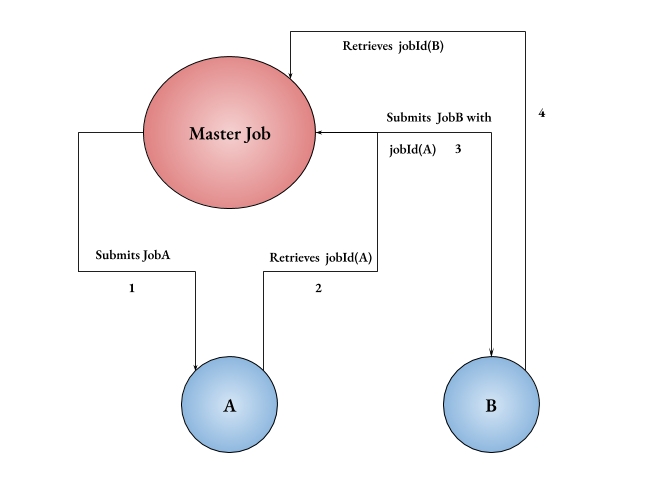
The master would:
- Submit the first job A through any of the client libraries. In python, it is boto3 or botocore. Once the job_submit request is through boto3, then
- Retrieves the jobId of A.
- Then use the jobId of A to submit job B.
- Retrieves jobId of B to submit jobs that depend on B
job_a = dict(jobDefinition='sample-jobdef', jobName='sample-name', jobQueue='sample-queue') client = boto3.client('batch') response_a = client.submit_job(jobDefinition=job_A.get('jobDefinition'), jobName=job_a.get('jobName'), jobQueue=job_a.get('jobQueue')) job_id_a = responde_a['jobId']
Once you have the jobId of job A, then you can submit job B stating that it depends on job A.
Note that job B must be of type SEQUENTIAL or N_TO_N depending on whether job A is a an Array Job or not345. In the code snipped given below note that job B has type SEQUENTIAL
job_b = dict(
jobDefinition='sample-defition-B',
jobName='sample-name-B',
jobQueue='sample-queue-B',
type=SEQUENTIAL)
response_b = (client.submit_job(jobDefinition=job_d['jobDefinition'],
jobName=job_b['jobName'],
jobQueue=job_b['jobQueue'],
arrayProperties=job_b.get('arrayProperties', None),
dependsOn=[
{
'jobId': job_id_a,
'type': job_b['type']
}]))
job_id_b = response_b['jobId']
-
Drawbacks
The AWS does not have an in-built mechanism to submit a workflow and automate it. One has to write a custom script to automate their workflows. A sample workflow automation code for tree depencies are given here. Though this is one of the draw backs, AWS provides its log-monitoring service Cloud Watchh and Alert Manager Simple Notification Serivice (SNS) for the batch jobs/workflow.
-
Cloud Watch for log-monitoring
Any job needs logs for debugging in case if it fails or if it doesn’t function the way it was designed to be. AWS provides CloudWatch log-monitoring system for both the log-monitoring as well as scheduling or triggering your AWS Batch Jobs.
-
SNS for Alert Manager.
You can integrate AWS Simple Notification Service with CloudWatch as an alert manager for all your applications. It provides both SMS and Email notifications. You can read more about them over here.
Annexure
Array Job
An array job is job run parallel or concurrently in same host or mutliple host machines. They share common parameters like job definition, vCPUs, and memory[cite]. AWS currently allows upto 10,000 array size. When an array job is submitted with array size 10, a single parent job is run. This parent then spawn 10 other jobs. These 10 child jobs would have job ID - parent_job_id:0 for the 1st job and so on to parent_job_id:9 for the last job.
Dependancies
-
In case another job (say job Y) depends on an array job (say job X). it can be either SEQUENTIAL or N_TO_N.
-
In case the dependant job (job Y) is SEQUENTIAL then the dependant job (job Y) would wait till all the array jobs (of job X) are completed.
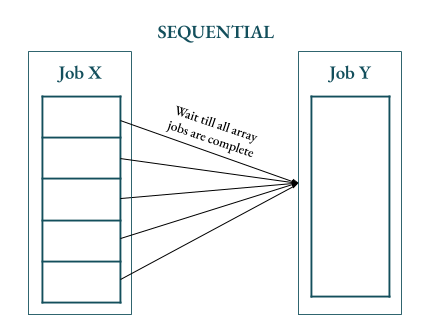
-
If the dependant job is N_TO_N then the dependant job should have the same array size as the job X. In this case each array job in Job Y would wait for the corresponding array job in Job X to complete. Job Y:0 would depend on Job X:0 and wait till and Job X:0 is completed. Job Y:1 would depend on Job X:1 and so on.
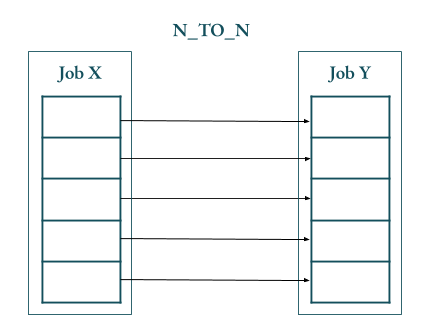
- Both in case of SEQUENTIAL and N_TO_N dependant jobs, cancellation or termination of any of the array jobs of Job X would lead to the cancellation of job X. This ‘moves’ job X to
FAILEDstatus.5
-
https://docs.aws.amazon.com/batch/latest/userguide/jobs.html ↩
-
https://docs.aws.amazon.com/batch/latest/userguide/create-job-definition.html ↩ ↩2
-
https://docs.aws.amazon.com/batch/latest/userguide/job_dependencies.html ↩
-
https://docs.aws.amazon.com/batch/latest/userguide/submit_job.html ↩
-
https://docs.aws.amazon.com/batch/latest/userguide/array_jobs.html ↩ ↩2